Comme beaucoup, j'ai utilisé git pendant des années sans utiliser l'index. C'est alors qu'un collègue se met à git et me parle de l'index… pas clair!
Et le hasard faisant bien les choses, arrive un cours Git avancé de Matthieu Moy, dont la page 21 reprend ce graphe très clair d'Oliver Steele dans sa page My Git Workflow:
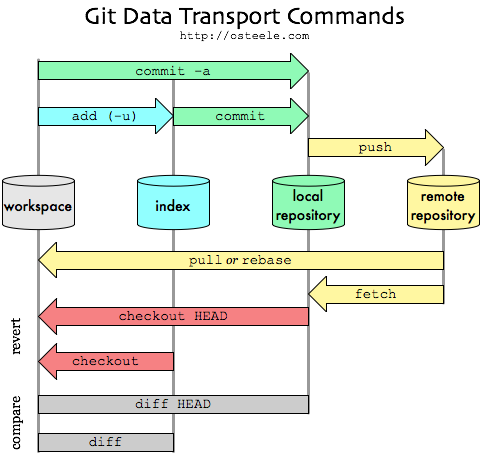
L'exemple que je trouve parlant est le développement d'une fonctionnalité… qui nécessite un petit refactoring… et on trouve un petit bug lors de ces modifs.
Grace à l'index, on va pouvoir faire trois commit indépendants et donc clairs : un pour la fonctionnalité, un pour le refactoring et un pour le bug.
Pour aller plus loin, on peut utiliser la commande :
git add -p [fichier]
qui va nous demander ce que l'on veut indexer dans les différentes parties qui change dans un fichier. Si on ne précise pas le fichier, il traite les fichiers modifiés les uns après les autres.
Aure exemple (un des premiers que j'ai réalisé): j'ai commencé des modifs de code et quelques jours suivants, je modifie le shéma (MCD) de la base, un fichier .dia.
git add doc/mon_fichier.dia git ci ajout des tables pour début de migration commentaire complet pour mon ci git pso
Seul mon_fichier.dia est commité, le code reste des autres fichiers modifiés ne l'est pas.
Autre point lié à l'index, il est souvent pratique, par exemple après quelques jours d'interruption dans son travail, de faire un git diff pour voir les derniers changements dans un fichier. J'avais tendance à ne pas ajouter à l'index des fichiers pour permettre cela. On peut ajouter à l'index et voir les modifications en utilisant la commande :
git diff --staged <fichier_à_visualiser>
# si on a définit un logiciel de comparaison
git difftool --staged <fichier_à_visualiser>
# j'ai ajouté un raccourci pour cette dernière dans mon .gitconfig :
ds = difftool --staged